A Tech Primer for Microservices Database Management

Content Map
More chaptersDo you agree that microservices are beneficial for various stakeholders involved in software development and deployment? Any objections or second thoughts? According to the research by Statista, 81.5% of companies already use microservices, while 17.5% are on their way to switching to microservices architecture. Only 1% of respondents refuse to adopt microservices. The numbers don’t lie - microservices are here to stay.
But this time, we will not discuss what makes microservices so popular; instead, we will focus on the angle of microservices database management and outline the common patterns for managing data in a microservices environment.
Introduction to Microservices Database Management
For beginners, it can be overwhelming to “digest” various terminologies related to microservices in a short period. Thus, we will introduce the fundamentals of microservices database management so that you can keep up with the basics before jumping to the list of database management patterns for microservices.
What Is Microservices Architecture?
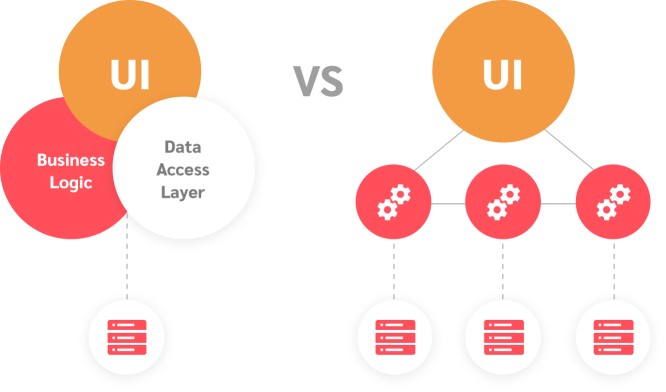
Microservices architecture, briefly referred to as microservices, is an approach to software development. In which a single application is developed as a suite of small and independent services or different components. That’s what they call micro-services.
Often owned by a small, self-contained team, each component runs in its own process and communicates with others using lightweight mechanisms, often an HTTP-based API. And each is assigned to its own designated data store. These data stores are often referred to as microservices databases, which are not shared with other services.
Microservices architecture enables greater scalability and agility as services or components can be deployed, tested, and deployed separately, which reduces the dependencies between development teams and allows them to proceed faster and more proactively from one another. Moreover, microservices enable the use of different data-storing technologies with each service, which boosts development speed as well.
Indeed, microservice architectures offer many benefits. They make applications easier to scale and faster to develop, facilitating innovation in the software development lifecycle and accelerating time-to-market for new features. On the flip side, microservices may also present loopholes in database architecture, such as maintaining data consistency, synchronization, and integrity among different services.
What Is Microservices Database?
Simply put, this is the definition of databases designed to support the architecture of microservices. Unlike single relational databases for traditional, monolithic applications, microservices databases are optimized to handle high-volume, distributed data workloads in more complex and dynamic environments. They provide scalability, reliability, and security for applications that make use of multiple services, as well as a foundation for modernizing legacy systems.
There are different types of microservices databases, such as relational databases, NoSQL databases, time series databases, and graph databases. Each of these types offers different benefits for specific types of applications. For instance, a time-series database is great for storing sensor data that needs to be analyzed in real-time. A graph database can be used to capture complex relationships between entities (people, places, etc.). In software development, a relational database is usually the default choice.
What Is Microservices Database Management?
As simple as the name implies, microservices database management refers to a sequence of practices that involves planning, deploying, and managing data for a microservice-based application. This process includes selecting an appropriate database type for each service and designing the database structure to support component-level operations, as well as configuring replication, backups, and other performance requirements.
When it comes to microservice database management, there are some key aspects to keep in mind:
Data Ownership
As mentioned earlier, each microservice is designed to “own its data.” In other words, data ownership means that every microservice manages its stored data independently and avoids coupling between services. It also means that microservices do not share data. Other services that need direct access to this data must do so through the owning service’s API.
Data Isolation
Due to data ownership, microservices are isolated from one another, meaning each service stores and reads from its own database, while communication between services happens through APIs or messaging protocols like RabbitMQ. The isolation prevents services from interfering with each other’s operations, making them more reliable as well as easier to maintain and scale. This helps maintain integrity between different parts of the application and prevent bugs due to unexpected interactions between different components.
Data Consistency
This is one key value to ensuring consistency – referring to the accuracy and validity – across different services’ databases. This can be done by using a message broker like RabbitMQ to send messages with updates whenever something changes in one service so the other services know they need to update their own data accordingly. Additionally, distributed transactions can be used to ensure atomicity and prevent conflicting reads and writes, while distributed locks can be used to prevent race conditions.
Data Persistence
This is the process of storing data even after the application has been shut down. Data persistence helps ensure data recovery in case of a crash and allows applications to continue running without interruption. Microservices database systems are configured with redundancies and backups, allowing continuous availability in order to attain this. These backup processes must be frequently tested to ensure they run as intended.
What Are the Microservices Database Management Patterns?

At this point, you must have gained a better understanding of what is involved in microservices database management, mustn’t you? Now, it is high time to have a glimpse at some data-related patterns used in this setup.
Database per Service Pattern
This is known as the most common and straightforward pattern of all to manage data in a microservices architecture. In this approach, each microservice has its own “private” database. The service accessing data cannot be shared with others unless through the API provided by that service. This means the data for the different services is completely isolated and that no other services are dependent on it.
The database per service pattern allows teams to work independently without having to coordinate their updates with other teams, which boosts productivity and enables rapid development. The trade-off of this pattern is that it can result in numerous databases and require more hardware resources to host them.
Shared Database Pattern
The second pattern involves using a single database for multiple services. Or it means the shared database pattern enables various services to access and store data in the same database. Hence, it lends a hand to minimizing the time and resources needed to deploy new applications while reducing hardware costs as fewer databases are required to be hosted.
Nevertheless, sharing a single database among various microservices can lead to complications. For example, it could inadvertently create service dependency, which can be problematic if one service needs to update its database schema, as all services sharing the same database will be impacted. This can impede how the teams can work independently or potentially slow development.
Saga Pattern
In a microservices architecture, transactions can span services, which can be a challenge given the distributed nature of the system. This is where the concept of Saga comes in. A Saga is a sequence of local transactions where each transaction updates data within a single service. If a local transaction violates a business rule and fails, the Saga then executes a series of compensating transactions to undo the influence of the preceding local transactions.
Implementing transactions using Sagas can help ensure data consistency across microservices, but it requires careful design and coordination among the different services involved. Various methods can be used to coordinate Sagas, such as choreography, where services publish events that other services subscribe to, or orchestration, where a central service (the orchestrator) tells the other services what to do.
Command Query Responsibility Segregation (CQRS) Pattern
CQRS is an architectural pattern used in a microservices setup. In this approach, instead of writing data directly to the database, services write their changes to an event log first. Then, separate service(s) (called “projectors” or “read models”) subscribe to the log and apply the changes to the database, ensuring that the data stored in the database is consistent with other services.
The main benefit of using CQRS is scalability. Read models can scale independently from written models, allowing for better performance when reading and writing data simultaneously. Additionally, it makes operations easier as it allows separate teams to manage read and write processes independently. One trade-off of this pattern is that it requires careful design and coordination among the different services involved to ensure data consistency.
Event Sourcing Pattern
This is a well-known pattern for microservices architectures. In the event sourcing pattern, instead of directly writing data to the database, services write their changes to an event log first. The events are then used to build up a view of the current state and store it in the database. This pattern helps with audibility as all changes made to a service can be tracked by reading through its event log. Additionally, it supports temporal queries, as historical data can be easily retrieved.
On the other hand, this pattern requires careful design and coordination among the different services involved to ensure data consistency. Additionally, it could incur extra costs if many events are stored in the log that needs to be queried and processed.
API Composition Pattern
This pattern enables microservices to read and write data from multiple services at once by using a single API. This reduces the latency of operations by decreasing service calls, and it also simplifies the development of complex operations that require data from multiple sources.
Nevertheless, this pattern can lead to complicated APIs with numerous parameters. It may also reduce the agility of services as changes in one service might have an effect on other services.
Domain Event Pattern
The domain event pattern is similar to the event sourcing pattern in that changes are stored in an event log. But instead of storing all events, services only store the relevant ones that have a direct impact on other services (called “domain events”).
This pattern helps reduce costs as fewer events need to be stored and queried. It also reduces coupling between services as only the relevant events are shared. Despite its benefits, this pattern requires careful design and coordination among the different services involved to ensure data consistency. Additionally, it could lead to a lack of audibility if domain events aren’t stored or the log isn’t queried frequently enough.
Database Sharding Pattern
This pattern involves distributing a single dataset across multiple databases (or shards). A shard contains a subset of the data, which allows for better performance since queries only need to return the data from one shard instead of all of them. This also helps with scalability, as the number of shards can be increased or decreased depending on the volume of data being processed.
The main challenge of using sharding is that it requires careful design and coordination among the different services involved to ensure data consistency, especially when writing data. Additionally, if one shard fails, queries may need to be re-routed to other shards, which could increase latency.
Hopefully, this post has done its job well to help you gain an introductory understanding of microservices database management as well as present to you the common patterns utilized in this setup. Having a clear understanding of the patterns and their trade-offs can help you make informed decisions when designing and implementing microservices architectures. Moreover, remember that there is no one-size-fits-all solution; each organization needs to evaluate its requirements and pick the solutions that work best for them.
Contact Orient Software, if you would like to outsource your IT needs to a dedicated team of experts. We are well-experienced in the world of IT outsourcing and capable of providing you with custom solutions that are secure, reliable, and of the highest quality. We strive to keep up with the latest industry trends in order to serve our clients’ needs better. Contact us today for a free consultation.

Trung Tran
Technical/Content Writer
Trung Tran
Technical/Content Writer
Topic: