There’s a situation you’ve probably seen more than once in your time working in tech: the engineering teams delivered exactly what was written in the ticket, and it still wasn’t what anyone actually needed.
When you delve deeper into the project to find the root causes, you realize the problem isn’t about missed deadlines or an incompetent team. The code was fine. The team did their job. Instead, the problem was that the requirement was never precise enough to build from. The end result is that what was intended and what was built were two different things. And the cost of that? It almost always shows up as a rework.
And that’s exactly what spec-driven development is designed to close.
However, spec as source development isn’t simply a new artifact that an engineering team produces; it also plays a crucial role in how they work before a single line of code is written. To understand why that matters, it helps to look at where things break down in the first place.
The problem: why traditional development creates rework

Software development teams typically follow a specific order when building an application. Traditionally, they have sprint planning, backlog grooming, code reviews, and QA cycles. And yet, rework keeps happening.
The reason behind this failure doesn’t always stem from a broken process (while original teams clearly have their own workflows). The reason is a structural one. To further explain this, let’s look at how requirements travel through a typical project.
In a nutshell, a typical project usually begins with the business stakeholder explaining what they need to a PM. The PM then translates that into tickets. The developer then builds from those tickets. And today, with the development of AI applications, we have an additional add-on step: an AI agent generates code from the developer’s prompt.
At every handoff, something gets lost as each translation adds a new layer of interpretation. Nobody is careless in this situation; it’s just that the information degrades over time as each person develops a different project understanding instead of working based on a single source of truth. By the time the requirement reaches implementation, it may look nothing like the original intent. Holding more meetings or conducting tighter tickets is only a temporary fix.
Imagine ten engineers prompting AI ten different ways, with no shared foundation underneath, what will happen to your code quality instead? The more code they generate, the faster wrong assumptions compound. A vague prompt doesn’t produce a small misunderstanding anymore. Rather, it produces an entire feature built on the wrong foundation. Without a formal spec, you are not directing your AI tools. You’re hoping it guesses right. As a result, rework will continue in the future simply because the structure didn’t change from the beginning.
How much rework actually costs?
Rework is not the same as refactoring or bug fixing. Refactoring improves code that already works as intended. Bug fixing corrects code that is broken. Rework is rebuilding something that worked exactly as written, but not as needed. It is the most expensive kind of failure because it only surfaces after significant time and effort have already been spent. The later the problem is detected, the more expensive the rework will be.
Industry research estimates that rework accounts for 30-50% of total software project costs. Which means, for a $1M project, that is up to $500K spent building things twice. And the origin of that rework? Studies consistently point to requirements - 78-82% of software rework stems from requirement-related problems, not technical ones.
Some direct costs when a project faces a “teardown” might include developer hours re-spent, repeated QA cycles, and delayed releases. Meanwhile, some less visible indirect costs could include stakeholder trust, team morale, and the features that never got built because the budget went to rework instead.
Understanding spec-driven development (SDD)

So what is spec-driven development, actually?
At its core, spec-driven development (SDD) is a methodology where a formal written specification is created before any code is written and serves as the binding contract between business intent and technical implementation.
Everything related to the project, from before, during, and after the development process, is recorded and compiled in the spec file: what the feature does, what it doesn’t do, and what counts as done. The detailed specification answers all the technical details, project requirements, business context, acceptance criteria, architectural constraints, and tech stack, etc., upfront, before a developer touches the keyboard.
One thing worth clarifying early:
In spec-driven development, the spec is not documentation. It is the source of truth.
While documentation simply describes what was built, a spec defines what must be built, and the entire team, from developers to automated test suites, uses it to determine whether the work is complete.
What a spec is - and what it is not
The word “spec” gets thrown around a lot in engineering teams. A Jira ticket. A Confluence page. A Slack thread where someone explained what they needed. People call all of these specs - and that confusion is the biggest barrier to SDD adoption.
So let’s be precise about what a spec actually is in the context of spec-driven development.
| A spec IS | A spec IS NOT |
|---|
| A structured document defining observable behavior | A Product Requirements Document (PRD) |
| Written before implementation begins | A Jira ticket or Confluence page |
| Machine-readable and testable | A Slack thread or email chain |
| A binding contract on inputs, outputs, and constraints | A design document describing how to implement something |
| A living artifact, maintained as the system evolves | A one-time document filed away after kickoff |
| The source of truth for both developers and CI/CD pipelines | A reference document only humans read |
The last point is worth sitting with. A spec isn’t just something your team reads before starting work. It’s something your automated test suite consults on every build to determine whether what was built matches what was specified. This is the foundation of behavior-driven development, where expected behavior is defined before implementation begins and verified automatically on every build. This characteristic is also how you can easily distinguish between a real spec and the typical static documents your team has written.
SDD vs. traditional development: key differences
In traditional development, the sequence typically looks like this: code written → tests written to match → documentation added afterward. The spec, if it exists (in the form of static documents), is only treated as an afterthought and is written after the software engineering project has been completed. This kind of documentation is often quickly forgotten afterward and may not even be updated to the latest status of the project.
In contrast, SDD operates in a completely different way and inverts that traditional process entirely, starting with spec written and approved → code built to satisfy spec → tests generated from spec → docs derived from spec. In other words, the same spec holds a central role throughout the SDLC and is considered the single source of truth for all project activities.
To see why SDD works, it helps to put it side by side with how most teams currently build software.
| | Traditional development | Spec-driven development (SDD) |
|---|
| Starting point | Business requirement or verbal brief | Formal written spec |
| When is the spec written? | After the fact, if at all | Before any code is written |
| What do tests verify? | That the code works as written | That the code matches the spec |
| When is misalignment caught? | In QA or production | In spec review |
| Source of truth | The code itself | The spec |
| AI agent input | Vague prompt | Structured, unambiguous contract |
The difference between spec-driven development and traditional development in the “AI agent input” row is worth noting. An AI agent working from a vague prompt fills in the gaps with assumptions. This is what practitioners call vibe coding, giving an AI agent a loose prompt and hoping the output matches what you had in mind. An AI agent working from a spec with a foundation for context engineering has no gaps to fill.
One thing is important for engineering leaders. In cost-first development, misalignment is discovered in QA or in production after days or weeks of work have already been spent. While in SDD, it is discovered in spec review, before a developer has touched the keyboard.
That’s where the 100x cost difference comes from. Foundational research from NASA and IBM, documented in peer-reviewed literature on software cost control, estimates that a bug caught in production can cost 100x more to fix than one caught during the design phase. SDD moves that discovery point as early as it can possibly go. This is also one of the outstanding strengths that sets this specification apart from the typical post-mortem method.
How spec-driven development works in reality
Understanding what SDD is conceptually is one thing. Knowing how it actually runs in practice is another.
At Orient Software, SDD follows five phases. In this process, each phase produces a concrete artifact used for the next phase, not just a meeting outcome or a conversation. It is this chain of artifacts that makes our SDD traceable and keeps intent aligned with implementation all the way through delivery. This also means that if anything goes wrong during the process, we can easily pinpoint exactly where the chain broke.
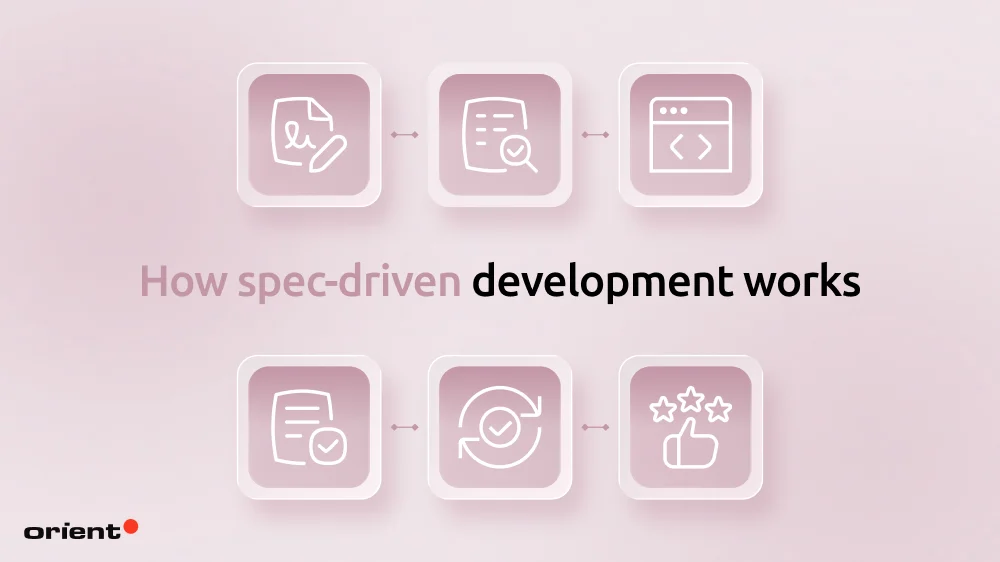
Specify - writing the contract before the work
Yes. The specification is written at the very beginning of every project we work with. This is considered one of the most important steps throughout the specification development process because it lays the foundation for everything downstream. If the specification is wrong or incomplete, it can negatively impact not only developers but also every task decomposed from it, including AI-assisted coding.
The people involved in this stage are all individuals who have context on the requirements, not a specific job title. They could be the PM, tech lead, or key stakeholders, depending on your project. They, together with Orient, will sit together in the same room before a single line of code is written to discuss and agree on the relevant criteria, such as what this feature does, what it explicitly does not do, what the inputs and outputs are, what constraints apply, what prior architectural decisions are already locked in, and what “done” looks like in observable, testable terms. Ensuring everyone is on the same page in this step is a must.
There is a discipline to writing outcomes instead of feature names. We are also applying this into spec writing tasks. In the specs, instead of writing as a feature name like “build an authentication flow”, teams need to specify what success looks like as outcome-writing: “A user can register, verify via email, and log in with session persistence”. This way of writing is specific enough that a developer knows exactly what to build, a tester knows exactly what to verify, and an AI agent has no ambiguity to fill with assumptions.
=> INPUT: Business requirement or user story
=> OUTPUT: Approved spec document
Plan - breaking the spec into trackable work
With an approved spec in hand, the next step is decomposition. The spec gets broken down into discrete implementation tasks. Each task is independently implementable, testable in isolation, and small enough to be reviewed as a single PR. Similar to outcome-writing, tasks also need to be noted clearly and specifically. “Implement authentication” is not a task. “Implement the email verification endpoint that accepts a token, validates expiry, and updates user status to active” is a task.
For example, one of our tech lead reporting on project progress might say: “Progress is now 4 of 7 tasks complete, mapped to spec requirements 2.1–2.3” instead of simply using the “in progress” term. While this is time-consuming and alters the usual workflow, it makes progress reporting meaningful and easier to track. The output of this phase is a technical plan - not just a list of tasks, but a traceable map from every piece of work back to a specific requirement in the spec.
For teams using AI coding agents, this phase is where the tool gets its most useful input. With a well-decomposed task with a spec reference, AI can generate output that is far more predictable than handing it an entire feature brief and hoping for the best.
=> INPUT: Approved spec document
=> OUTPUT: Implementation plan with full task-to-spec traceability
Implement - building within the spec’s boundaries
This is where code gets written, but the starting point looks different from traditional development. Because the spec exists upfront, it can generate scaffolding before implementation begins. Our developers and AI agents then build against that scaffold. Tools like GitHub Spec Kit make this concrete - the spec drives commands that produce server stubs, mock servers, and an initial test suite. The result is code generation from a defined contract, not a vague prompt.
It is worth noting that everything listed in the spec document is a requirement that the implementation must satisfy, not a suggestion to keep in mind. This means, if the spec says a response must return within 200ms under normal load, the development teams must meet that authoritative constraint exactly.
The rule that makes SDD durable in practice at Orient Software is that the spec is never bypassed when inconvenient. When implementation reveals a flaw in the spec (e.g., an edge case that wasn’t considered, a constraint that turns out to be technically impossible, a business rule that needs refinement), the spec gets updated first, no matter how much effort it takes. And of course, these changes go through the same review and approval process as the original spec. Only then does implementation continue.
=> INPUT: Approved spec document + implementation plan
=> OUTPUT: Working implementation + spec-generated tests
Validate - confirming what was built matches what was specified
Unlike traditional QA, where all testing is done manually by humans at the end of the sprint, validation in SDD is an automated process that runs on every commit. Spec-based tests live in the CI/CD pipeline, so they already know exactly what the correct behaviors should be. In situations where the code does not match the spec, the pipeline stops immediately and flags it, helping developers know within minutes, not days, in a sprint review or a production incident.
Failures in spec-driven development are also defined very differently and are divided into two categories: specification failure (the specification was correct but the code didn’t satisfy it => the requirements need to be revised) and implementation failure (the specification was correct, but the code didn’t satisfy it). This distinction matters as it tells our teams whether our process broke down or our understanding did – specifying the problem to find a solution.
=> INPUT: Working implementation + spec-generated tests
=> OUTPUT: Validated delivery or identified divergence with failure classification
Maintain - keeping the spec alive as the system evolves
If you create the spec document only once and then never touch it again or intend to update it in the future, you’ve recreated the exact problem SDD was designed to solve – creating an outdated document that nobody trusts.
This is how Orient maintains the spec. When a requirement changes, no matter how small, the specification must be updated first. In other words, the team needs to continuously update the specification document to ensure it closely reflects the project’s reality.
Specs live in source control alongside the code, with the same PR review process. When a feature is deprecated, its spec is archived, not deleted. That archived spec becomes a traceable record of what the system was designed to do and why. This is especially valuable when working with existing systems. New engineers and AI agents can read the spec to understand the constraints inside an existing codebase and work safely within existing code without breaking things they don’t fully understand yet.
=> INPUT: Delivered feature + evolving requirements
=> OUTPUT: Versioned living spec that remains the authoritative source of truth
What goes into a good spec
However, like all other types of documentation and writing, a spec is only truly useful when written correctly. A vague spec (despite being called a spec) produces the same problems as the informal documents traditional development already relies on. With a bad spec, developers will still fill in the gaps with assumptions, AI agents will still generate code based on guesses, and the rework cycle will start again.
So, what does a well-written spec look like? It’s one that answers the following six questions.

- Outcomes - what “done” looks like in observable terms: Done in SDD is not defined by “the feature is built” but rather by what is more specific, observable, and testable. “A user can reset their password by entering their email, receiving a reset link within 60 seconds, and setting a new password that meets the defined complexity rules” - this is done.
- Scope boundaries - what is in, and explicitly what is out: Not only does it define what the feature does, but a good spec also defines what the feature doesn’t do. Explicit out-of-scope boundaries prevent scope creep, prevent developers from building things that weren’t asked for, and prevent stakeholders from assuming something was included when it wasn’t.
- Constraints - non-negotiable technical and business rules: Every feature operates within constraints, response time limits, for example. Constraints act as hard boundaries that the implementation must stay within. Leaving all related constraints in the spec helps the test suite catch them automatically instead of discovering them in production.
- Prior decisions - architecture and rationale already locked in: A good specification should include architectural decisions, technology choices, and patterns the team has already committed to. The purpose of including prior decisions in the spec is to prevent developers from relitigating them mid-implementation or making choices that contradict them.
- Task breakdown - implementation work at testable granularity: The spec breaks the feature into independently implementable tasks, and each task needs to be small enough to be reviewed in a single PR and specific enough to be tested in isolation. These tasks, once broken down, will be fed directly into the Plan phase.
- Verification criteria - the specific conditions that prove completion: Verification criteria are the exact conditions that must be true for each task and for the feature as a whole to be considered complete. These become the basis for the automated tests in the Validate phase.
Why SDD stops the rework cycle
Everything covered so far comes back to one practical outcome: less rework. Here is exactly how SDD delivers that.

Catching misalignment in spec review, not in production
In traditional development, nobody finds out that the wrong thing was built until a QA discovers it or the feature is in production. Despite dedicating significant time and effort to the feature, the misalignment was discovered late, forcing the teams to start over.
SDD moves that moment earlier with specifications. Because specifications are written before anyone writes code and are approved by stakeholders, the misalignment gets caught sooner at the discussion stage. Instead of spending weeks fixing a wrong assumption after implementation, it now costs an hour to fix the same thing in a spec review.
The results? Teams using spec-driven workflows report up to 75% reduction in integration cycle time as problems surface even before the implementation steps have taken place.
Frontend and backend can be built at the same time
In most development teams, the frontend waits for the backends. Backends are responsible for building the API first, and then the frontend builds against it afterward. It’s a typical process, and let’s admit it’s time-consuming.
SDD changes that. Once the spec is approved, it generates a mock server with realistic responses based on the spec’s defined schemas. At this stage, frontend can start building immediately, and backend builds in parallel - no stage needs to wait for another. When both sides are done with their jobs, integration is straightforward because they all have their code files derived from the same spec.
For a four-week feature, this can recover a week or more.
Delivery estimates become commitments, not guesses
Without specification, all delivery estimates are predictions. It’s difficult to determine precisely how much time a person/team will need to complete a given task. While a sprint usually starts with a specific plan, something shifting by midweek can cause things to deviate from the original plan.
With the specification, that stops happening as often. Because everything is predetermined from the very beginning, before developers even touch a keyboard, they (including teams on the same project) can proactively define what is being built and know the specific timeline for delivering a feature. In general, the estimate on the other side of a spec approval gate is based on known information, not assumptions.
However, this doesn’t mean surprises never happen, as we can’t control the future. Delays will still occur, but by stopping, updating the specifications, getting it reviewed, and then continuing, a delay in specification-driven development is a controlled delay. Everyone knows why the timeline shifted, what changed, and what the new plan is. That’s a very different situation from a mid-sprint pivot where nobody agrees on what the requirement actually meant in the first place.
Compliance evidence that exists without extra work
Unlike traditional software development, where teams handle compliance requirements by producing documentation after the fact, SDD ensures that necessary documentation is always available before it’s requested. Digging through old tickets, writing up summaries, and hoping the right people are still around to remember the decisions made - like people used to - slows down the process, increases costs, and often leaves things incomplete.
By recording what the system was designed to do, what constraints it operated under, and what was explicitly out of scope at the very beginning of the project, the spec acts as a natural byproduct of how the team works, not a separate effort on top of it. This ensures that when everything is required, you and the project are already prepared.
For teams building AI systems, this is especially relevant. The EU AI Act, taking effect in August 2026, requires high-risk AI systems to demonstrate evidence of design intent. A spec repository satisfies that requirement directly with no additional documentation work needed.
Engineers leave, but the knowledge doesn’t
One of the biggest reasons why rework keeps happening is this: your documentation remains too passively dependent on the senior engineer who wrote it. And what happens after they leave? The knowledge goes with them. Those who remain, instead of continuing the project’s progress, and the new hires, instead of immediately getting started, are left feeling lost and unsure where to begin, working based on assumptions and leftover information.
A spec repository changes that. A new engineer can read the spec and understand what a module does, what it must not do, and why, without needing someone to explain it to them. As a result, onboarding gets faster. And when people leave, the knowledge stays.
The spec is where it starts

Spec first development is not a new idea. API teams have been doing something similar under “design-first” for years. But it never became standard practice because human developers could fill the gaps by asking questions, using judgment, and figuring things out. However, in the age of AI, where AI coding agents play an indispensable role as powerful assistants, things have changed.
AI cannot ask questions and use judgment like humans. Feed them a vague prompt, and the code generated on the other side is built on assumptions nobody agreed on. The more they generate, the faster those assumptions compound. That’s what changed. A formal spec went from good practice to a hard requirement.
The teams that figure this out early stop fighting the same battles over and over. This means less rework, fewer mid-sprint surprises, and faster onboarding. And it all traces back to one habit - writing only the spec before anything else.
Spec-driven development is how Orient Software approaches every engagement. Regardless of industries, processes start with a spec that your business can read, your engineers build from, and your AI agents act on. It is how we make sure what gets built is what was actually needed, and that it stays that way as your product grows. Contact us if you are looking for a software partner that builds with your future team in mind, not just your current one.







