Top Four AI Use Cases in Fintech
12/02/2026 ![]()
Building AI doesn’t have to be overwhelming if you understand the AI development lifecycle; you can turn complexity into a clear, manageable process.

Content Map
More chaptersAs of 2026, thousands of AI tools and AI-powered services have been introduced to users. This creates immense pressure for companies to keep up with the growing AI race, especially when consumers are now used to AI tools and expecting businesses to always have AI assistance available.
However, with the increasing sophistication of this technology, the development process understandably seems intimidating. The assumption is often that the process is long, complicated, and expensive. This doesn’t have to be the case. As long as you take a structured approach, do enough research, and consult experts, the AI project will be like any other software development project - challenging but gratifying.
Today’s article explains everything you need to know about the AI development lifecycle, breaking each large step down into smaller ones, along with some challenges to be aware of. Let’s dive right in!
Key Takeaways:

Do you really need to know all the steps before jumping into an AI development project? The short and long answers are both yes. There are long-term benefits to doing careful homework before the actual project begins.
Seeing how AI moves from idea to production allows you to implement efficient risk management strategies. This means:
In short, reducing risks is not only about safeguarding the data but also about fostering transparency and an ethical AI tool.
Grasping the AI development lifecycle means you can plan ahead to optimize costs. The team can plan resource allocation for each stage of the development process, ensuring there are always enough hands on board, even in scenarios when a team member decides to quit unexpectedly.
The team can also research and consult with experts to determine beforehand which criteria to focus on during each stage, preventing expensive mistakes and rework. This also means putting in place effective monitoring systems based on clear key performance metrics (KPI) and automating repetitive, mundane tasks.
The AI lifecycle is foundational to effective MLOps, or machine learning operations. MLOps is the key to transforming from an ad-hoc and manual approach to systems that are scalable and production-ready. Having a clear idea of what steps the AI development process entails means the team can:
According to IBM, model drift occurs when a machine learning model’s performance declines over time because the underlying data or the relationship between inputs and outputs changes. Also known as model decay, this issue can lead to inaccurate predictions and unreliable decisions if left unaddressed.
AI models are trained on one version of reality, and they solely rely on this version to generate replies to users. However, the world never remains static, and data is constantly changing or updated. AI may not be able to capture all these changes in its model and assume non-existent relationships, resulting in wrong results. One or two mistakes here and there might not seem like a big deal, but in the end, businesses can suffer from faulty business decisions, bias, unfairness, and even legal risks.
Gaining insight into the AI development lifecycle allows teams to employ continuous drift management, such as monitoring data distribution, uncovering the root cause, using statistical analysis tests, and so on.
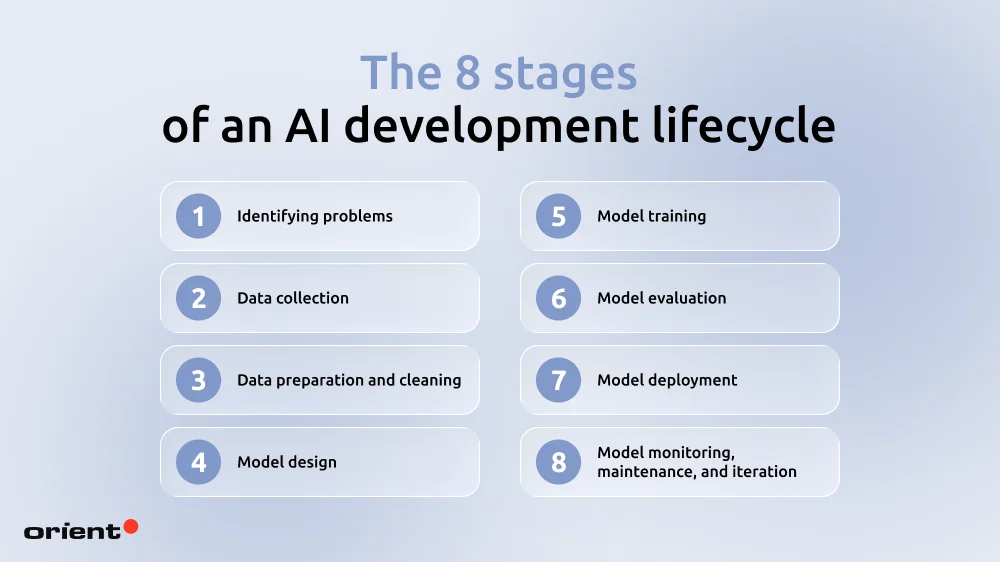
The very first step is what some people call the “exploring” phase. What this means is that before any actual development begins, the team needs to sit down and explore every aspect involving the AI project.
Data collection is a foundational step for building a successful AI model. AI learns patterns from the data provided to generate the most optimal response; thus, the data needs to be high-quality so the model can make accurate predictions and decisions.
First things first: where do businesses even collect the data from?
Data sources can originate from public, private, human interactions, or even synthetic sources.
Then we move on to the next step: data collection method.
After the collection of data, there are still a few more steps to go through before moving to the next stage of AI development:

Collected raw data is often not used directly for AI training since there are multiple inconsistencies, missing values, or noise that can negatively impact the model’s overall performance.
The fourth step is selecting a suitable AI model. This comes down to your computational resources, use case, and training data.
While there are a huge number of algorithms and architectures, the biggest and fanciest ones aren’t always the right answer; you need to carefully consider the problem type and real-world application. Here are a few examples:
In short, outline as clearly as possible the problem you’re trying to solve. Sometimes, conventional learning models can perform a task perfectly.
Training a generative model from scratch isn’t only extremely costly, but it also takes a long time. It is often recommended to use pretrained models and fine-tune them as you go. However, this is not to say that there is a universal pretrained model, as there are multiple sizes and architectures involved in ready-made ones. You can also combine multiple models if it’s appropriate, and remember to integrate security measures from this very step.
All the preparation leads to the step where you actually build the AI: model training. In this step, the model is exposed to the prepared data, where it learns to identify patterns and data relationships while it also adjusts parameters to produce the most accurate response.
The AI training process directly impacts the quality of AI’s responses; hence, it is important to address the following problems:
Evaluating and testing the model is a crucial step. It tests how well the model generalizes new, unseen data. This is often done with a completely new dataset to evaluate how well the model performs, using a number of metrics based on specific problems and business goals. Here are a few examples.
Metrics involving classification (prediction metrics):
Some regression metrics include:
In addition to these metrics, the model also goes through a number of other rigorous tests, like performance testing, A/B testing, end-to-end tests, integration tests, and more.
Once the evaluation is satisfactory, it is time to move the AI model to the production environment, where it will solve problems in the real world. An important decision to make involves the deployment model of the AI model.
Choosing the deployment environment isn’t the end of this step. Teams also need to pay attention to:
Deploying doesn’t mean you never need to train the AI model again. While monitoring the model’s performance, companies also need to:
Above are the main steps of the AI development lifecycle. Following this framework mitigates risk while creating a high-performing and scalable AI model.
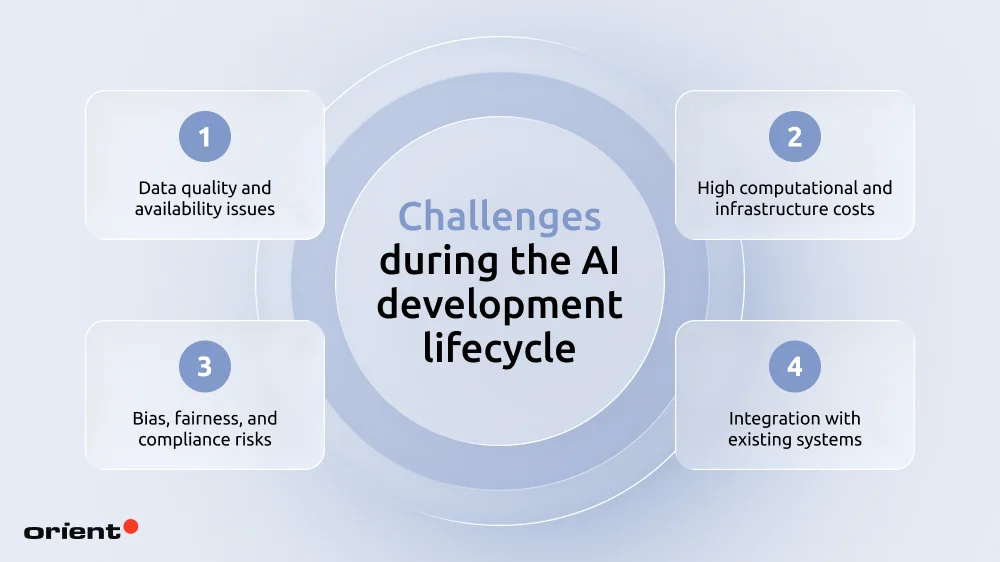
This article won’t dig too deep into all the challenges during the development process, but here are some of the most common problems teams run into and possible solutions for them.
Solution: Standardize and clean data through governance frameworks, automated pipelines, and regular audits.
Solution: Optimize and go cloud-first. Use cloud infrastructure, model optimization (e.g., pruning, quantization), and hybrid setups to reduce compute costs without sacrificing performance.
Solution: Implement responsible AI practices. Use diverse datasets, run bias audits, and adopt governance frameworks.
Solution: Use API-first and phased modernization. Connect AI with legacy systems via APIs, middleware, or hybrid architectures instead of full system overhauls.

Understanding the AI development lifecycle gives you a clear roadmap to follow, whether you are starting out on your project or scaling the current AI solution. After all, organizations that master the AI development lifecycle will be better positioned to adapt and stay ahead in an increasingly competitive, AI-driven market.
Another way to speed up your development lifecycle even further: have Orient Software as your partner. With 2 decades of experience and dozens of successful projects, we are confident that we can bring your visions to reality. Contact us today!
Writer
Writer
We’d love to connect with you and figure out how we can contribute to your success. Get started with an efficient, streamlined process:
Schedule a Meeting
Discuss your needs and goals, and learn how we can realize your ideas.
![]()
Schedule a Consultation Call
Discuss your needs and goals, and learn how we can realize your ideas.
Examine solutions, clarify requirements, and onboard the ideal team for your needs.
![]()
Explore Solutions and Team Setup
Examine solutions, clarify requirements, and onboard the ideal team for your needs.
Our team springs into action, keeping you informed and adjusting when necessary.
![]()
Kick Off and Monitor the Project
Our team springs into action, keeping you informed and adjusting when necessary.
Drop us a message, and we'll get back to you within three business days.
21
Years in operation
100
Global clients
Full Name
Company
Website
Tell us about your project
*By submitting this form, you have read and agreed to Orient Software's Term of Use and Privacy Statement